eldr.ai | ELDR AI Model Parameters
If you haven't already, please have a look at the
AI Model Structure
guide before going through this tutorial as this guide is an extension of that.
ELDR AI allows you to easily create highly dynamic AI Models. It does this by giving access to a wide range of parameters at all layers.
For this tutorial, please open up the "Create Model" page in ELDR AI and keep in mind the structure diagram from the last tutorial in mind.
We will go through each section of the Create Model page and discuss the related parameters that you can change:

Here you can dictate the number of hidden layers and the number of neurons within each layer. The default values are shown which should be good
enough for most small to medium models however if you have complex data you will need to increase the number of neurons. As you get used to ELDR AI
you will soon learn how many neurons and layers are required.

In the structure tutorial we talked about Activation as a determiner of how much influence each neuron has on the other neurons. Here you can change that
using the Network value. Sigmoid means each neuron always has some influence on the next neuron and
is determined by the inputs to the neuron. Relu on the other hand allows the neuron to have influence on other neurons only
if a threshold is reached. They both therefore behave quite differently and alter learning dynamics. Both will work in the majority of cases but it is definitely
worth experimenting with. By default sigmoid is chosen. If you are unsure, stick with sigmoid.
In the structure tutorial we also talked about the optional activation at the output layer. In the majority of cases you will not need this however we
have put it in for users who need this in their models. Using a network activation of relu with output activation of sigmoid is quite common.
One interesting scenario where output activation is used in the output layer is softmax.
In the tutorial section we discussed multiple outputs where we One Hot Encoded them, e.g. used 0s and 1s to specify
options within an output. However using softmax you can use normal numbers in the outputs. E.g. if you have outputs of 1,2,3,4 denoting a customer-type,
softmax can be used at the output layer. Softmax has the effect of normalising the outputs and making the sum of them all equal to 1, meaning you maintain
the 1 output at the same time as being able to determine an output range e.g. 1,2,3,4 would be represented as 0.1,0.2,0.3 and 0.4. This allows the Model to
learn as if it were dealing with 0s and 1s. Again it is useful to experiment with output activations but the default is "none".

In the structure tutorial we spoke about "Loss Adjustment" as a large determiner of learning. Here you can change which method of loss adjustment is used.
Below is a guide on what's best to which purpose.
MSE (Mean Squared Error) - default setting. A good all-rounder suitable for most models especially regression (purely numerical).
If you are unsure or your models aren't working with other loss functions, use this one.
MAE (Mean Absolute Error) - excellent for regression problems where there are outliers.
NLL (Negative Log-Likelihood) - use for multi-output classification scenarios - must be used with Softmax
CE (Cross Entropy) - use for binary-output classification scenarios - must be used with Softmax
HEL (Hinge Embedding Loss) - can be used as an all-rounder. Is good when IPC is combined with binary-output classification
KLD (Kullback-Leibler Divergence) - use for complex regression models and multi-output cases
Again - it is useful to experiment with loss functions. As you get to know ELDR AI and your data, you will get used to choosing the most
appropriate loss function.

As mentioned a few times, learning or training in models occurs by constantly changing the influence of neurons over other neurons. This is done in
cycles or loops and in AI these are called "Epochs". In this section you can change the maximum number of Epochs. The default Epochs is 10,000 which
we suggest you start with when training a new model as this is usually enough Epochs to determine if you model is working or not. It's always better to
start with lower Epochs until you know your data is working/model is training.
We have also spoken about Loss several times. Here you can dictate a target Loss. The higher the Loss value here to the more precise you want your model
to train. During training Loss actually gets converted to 1/Loss, so the higher the number you select here, the smaller the loss required during
training. Again, 1000 is a reasonable value to start with until you are satisfied your model is learning.
For regression problems you can go very high with this, whereas for models with a lot of IPCs, 100 to 1000 will likely be sufficient.
Also in this section you can set a maximum training time. Again, start off low e.g. 5 minutes (default) until you are absolutely sure your data and model is working.

Here you can determine if Batch Normalisation is applied (default "no") as well as the probability of applying Dropout (default 0). It's advisable
to keep below 0.5 for dropout and only use where you have a lot of neurons. Again, experimentation will help you understand when to use it, based on
your data etc.
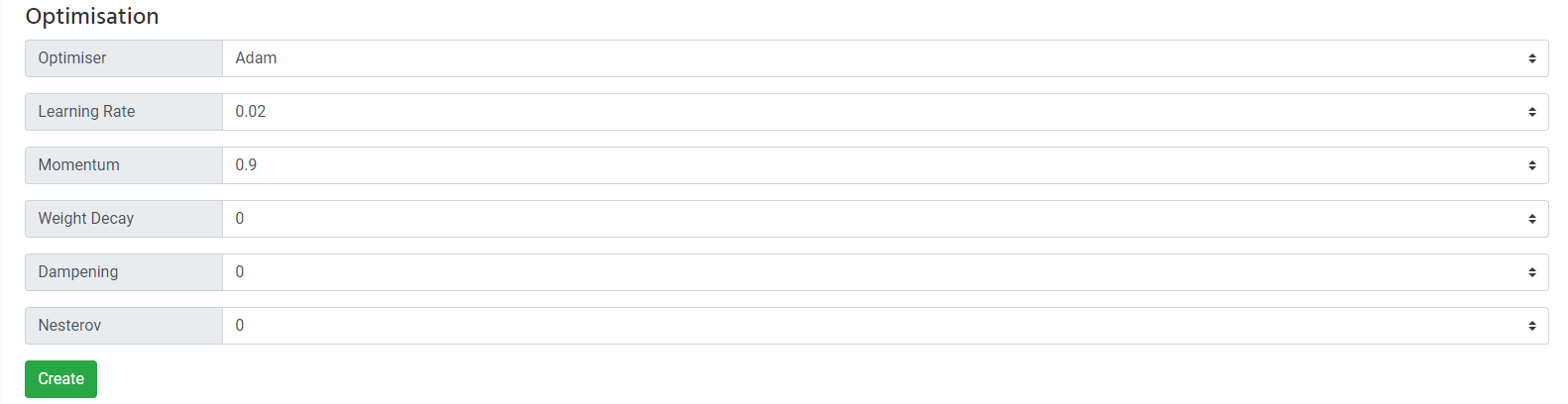
Optimisation is the process that changes the neuron influence as part of loss adjustment.
Optimiser - Broadly speaking, Adam is considered the fastest, SGD is considered the most accurate. Both are excellent though.
If in doubt use Adam (default) - we think it's slightly better overall
Learning Rate - a faster learning rate can result in less accuracy so you have to strike a balance. 0.02 is a safe bet.
For situations where you need high accuracy, choose a lower learning rate such as 0.003.
Momentum - helps stop learning "sticking" in one place - 0.9 is ideal for most situations - SGD Only
Weight Decay - helps prevent "over fitting" where your data fits the model so well the model is poor when shown data it hasn't seen before e.g. during prediction
Dampening - dampens/modifies the momentum - SGD Only
Nesterov - works a bit like momentum - has been reported to improve SGD - SGD Only
That concludes the ELDR AI guide to AI Model Parameters.